Python Program To Calculating Student Grade
- realcode4you
- Apr 7, 2022
- 5 min read
Requirement Details
The aim of this exercise is to process a file containing marks for a university module. The
input file will have the format
student.txt
5 30
1991111 65.5 45.5
2031234 75.5 68
2012345 33 50
2019734 55.5 51.5
2187345 39 47.5
...
...
The first line of the file contains the number of students and the percentage coursework
weighting, e.g. the 30 in this example denotes that the coursework comprises 30% of the
overall module mark (with the exam making up the other 70%).
Each subsequent line contains (in order) a registration number, an exam mark and a
coursework mark. The number of such lines will match the number of students.
Write a program that will open such a file, read the first line and create a 2-dimensional
NumPy array where number of rows is the number of students and each row has 4
elements. (Initialise this array using a call to the array function with an argument
[[0,0,0,0]]*n, where nis the number of students.)
The program should then read the remaining lines line-by-line and use the input values to store in a row of the array the registration number, the exam mark, the coursework mark and the overall mark (calculated using the exam mark, the coursework mark and the weighting). You may assume that all lines will contain the correct number of marks and the number of students will match the number specified on the first line.
Having generated the array, the program should then create a 1-dimensional array with n elements, but with a structured date type with 4 integers and one string as the components). (Use a list containing multiple copies of a structure with default values (e.g. zeroes and an empty string) as the argument to array.)
From the data in each row of the first array the program should generate a structure containing the student’s registration number, exam mark, coursework mark and total mark, all rounded to the nearest integer, and a grade string to be calculated using the rules below and store this in the corresponding element in the second array. (You can round a real number n to the nearest integer using round(n).)
The program should then produce a version of the second array sorted by overall mark
and output this array to a file (using a single call to the print function of the form print(array2, file=f)).
It should finally output to the screen/console the number of students who have first, second and third-class marks, the number of students who have failed and the registration numbers of the students who have failed.
Rules for calculating grades
Any student with a rounded mark of less than 40 for either the coursework or the exam has failed, irrespective of the overall module mark. For all other students a rounded overall mark of 70 or more has a first-class grade, a rounded mark between 50 and 69 (inclusive) has a second-class grade, a rounded mark between 40 and 49 has a third-class grade, and a rounded mark below 40 fails.
Implementation:
#%% Open the students.txt file and l;oad it into a numpy array
import numpy as np
# variables to store the contents of the firat line of the file
num_students, percent_coursework = 0, 0.0
# open the students.txt file and load it into a file
with open("students.txt") as students_file:
# get the raw line by line data from the file, stipped of
# whitespaces and split into arrays. In other words, file_data
# is a list of lists
file_data = [line.rstrip().split() for line in students_file]
# get the first line, and unpack it into the number of students
# and the percent course work
_1st_line = file_data[0]
num_students, percent_coursework = int(_1st_line[0]), float(_1st_line[1])
# get a list of students that will be loaded into the numpy array later
_ = file_data[1:] # select from the 2nd item in the list
stud_list = [(int(split_data[0]), float(split_data[1]), float(split_data[2])) for split_data in _]
#%% Load the file data into a 2D numpy array
# initialize numpy array
stud_array = np.array([[0,0,0,0]] * num_students)
# load stud_list into array
for idx in range(0, num_students):
row = stud_array[idx] # a row in the numpy array
stud_item = stud_list[idx] # an item in the student list
# iterate over all fields of the item in the
# students list, and copy it into the row of the numpy array
for field in stud_item:
# save registration number
row[0] = stud_item[0]
# save exam mark
row[1] = stud_item[1]
# save coursework mark
row[2] = stud_item[2]
# compute and save overall mark
row[3] = (stud_item[1] * (100 - percent_coursework) + stud_item[2] * percent_coursework) / 100
#%% Create a structured numpy array to hold the student assessment details and the grade
stud_grade_array = np.array([(0, 0, 0, 0, "") for i in range(0, num_students)],
dtype=[('regno', np.int32), ('exams', np.int32), ('cwork', np.int32),
('total', np.int32), ('grade', (np.str_, 15))])
#%% compute grade
def get_grade(stud):
'''
Computes the grade of the student
Parameters
----------
stud : TYPE
A row in the numpy array that represents a student
Returns
-------
str
A string representing a grade; either 'First-Class', 'Second-Class'
'Third-Class', or 'Fail'
'''
# check if either exam score or coursework score of student < 40
if stud[1] < 40 or stud[2] < 40:
return "Fail"
else:
if stud[3] >= 70:
return "First-Class"
elif 50 <= stud[3] <= 69:
return "Second-Class"
elif 40 <= stud[3] <= 49:
return "Third-Class"
else:
return "Fail"
#%% load stud_array into students grade array
for idx in range(0, num_students):
stud = stud_array[idx]
stud_grade = stud_grade_array[idx]
for field in stud:
# save registration number
stud_grade[0] = stud[0]
# save exam mark
stud_grade[1] = round(stud[1])
# save coursework mark
stud_grade[2] = round(stud[2])
# save overall mark
stud_grade[3] = round(stud[3])
# compute grade from overall mark
stud_grade[4] = get_grade(stud)
#%% sort the array in descending order, using array slicing notation
stud_grade_array[::-1].sort(order='total')
#%% save to file
# this version saved to file in a way that would make
# reading from the file impossible
with open("students_grade.txt", "w") as sf:
print(stud_grade_array, file=sf)
# this version did a better save to file that made
# it easier to read from the file later
# with open("students_grade.txt", "w") as sf:
# lst = list(stud_grade_array)
# final = [f"{regno} {exam} {cwork} {total} {grade}\n" for (regno, exam, cwork, total, grade) in lst]
# print(*final, sep="", file=sf)
#%% display stats for stud_grade_array
_ = list(stud_grade_array)
_1st_class = [e for e in _ if e[4] == "First-Class"]
_2nd_class = [e for e in _ if e[4] == "Second-Class"]
_3rd_class = [e for e in _ if e[4] == "Third-Class"]
_failed = [e for e in _ if e[4] == "Fail"]
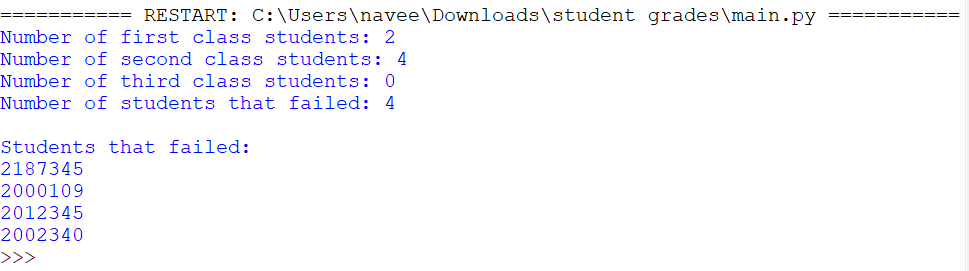
print(f"Number of first class students: {len(_1st_class)}")
print(f"Number of second class students: {len(_2nd_class)}")
print(f"Number of third class students: {len(_3rd_class)}")
print(f"Number of students that failed: {len(_failed)}")
# get registration number of students that failed
print("\nStudents that failed:")
for std in _failed:
# print the registration number of std
print(std[0])
Output:
Here you have all programming related help which is related to basic to advance level. Hire realcode4you expert and get all programming related help with an affordable price. We have group of 15+ python programming expert which have more than 5+ year of working experience.
You can send your assignment requirement details at:
realcode4you@gmail.com
Comments