Face Recognition using Support Vector Classification Method | Face Recognition Assignment Help
- realcode4you
- Jun 16, 2022
- 4 min read
Obtaining Data
Let us use fetch_lfw_people from sklearn.datasets to load the labeled faces in the Wild (LFW) people dataset. Run the following cell to check whose face images are included in the dataset. There are 1348 images, and the size of each image is 62 by 47.
from sklearn.datasets import fetch_lfw_people
faces = fetch_lfw_people(min_faces_per_person=60)
"""Whose images are there"""
print(faces.target_names)
"""The size of the dataset"""
print(faces.images.shape)15 face images must be put into three rows and five columns
import matplotlib.pyplot as plt
"""Plot some images"""
fig, ax = plt.subplots(3, 5)
fig.tight_layout() # to adjust spacing between subplots
for i, axi in enumerate(ax.flat):
axi.imshow(faces.images[i], cmap='bone')
axi.set(xticks=[], yticks=[],
xlabel=faces.target_names[faces.target[i]])output:

Splitting the dataset into a training set, a validation set and a test set You may first split the whole dataset into a training set and a test set, then further divide the training set into a smaller training set and a validation set. In this exercise, let us keep 35% of the total data in the test set; and 30% of the training data in the validation set.
from sklearn.model_selection import train_test_split
#values #labels
Xtrain, Xtest, ytrain, ytest = train_test_split(faces.data, faces.target, test_size = 0.35,
random_state=42)
#training set input # traning set label
#for Cw we only do this one split
SXtrain, Xvalid, Sytrain, vtest = train_test_split(Xtrain, ytrain, test_size=0.30,
random_state=42)Normalise the training set and the validation set
Note that in this step the scaling parameters should be obtained from the smaller training set only. You need to use the same parameter to normalise both the smaller training set and the validation set, which can be done using the method transform() of StandardScaler.
from sklearn import preprocessing
scaler = preprocessing.StandardScaler().fit(SXtrain) # fit gives mean values and std value bcoz we will use that
#value for both the sets
"""Scale the smaller training set"""
scaled_trnX = scaler.transform (SXtrain) # first split the smaller training set
"""Scale the validation set"""
scaled_valX = scaler.transform(Xvalid)Choose the most suitable parameters by comparing results on the same validation set
You will fit an SVM with an RBF kernel on the smaller training set. Have a look at how to use a C-Support Vector Classification from sklearn first. Please pay attention to how to assign a kernel type, C value, and gamma value in SVC, and how to use the fit method and the predict method.
In this task, you will choose a suitable gamma value from three values: 0.0005, 0.001 and 0.0007; and use a fixed C value. For example, C=10.
You need to use one of those three gamma values mentioned above. Report the accuracy rate of the model using metrics.accuracy_score. You can produce more performance metrics using classification_report.
from sklearn.svm import SVC
#you need to specify what kernel to use for CW we will use RBF
svc1 = SVC(kernel='rbf', class_weight='balanced', C=10, gamma=0.0005)
model1 = svc1.fit(scaled_trnX, Sytrain) # input is normalised bt we will use the correspdin label information
"""The fitted model should be validated on the scaled validation set. """
vyfit1 = model1.predict(scaled_valX)
"""Performance measurements"""
from sklearn import metrics
print('Accuracy:', metrics.accuracy_score( vtest, vyfit1 )) # ground trueth i.e the label of validation test compared with the
from sklearn.metrics import classification_report
print(classification_report(vtest, vyfit1,
target_names=faces.target_names))output:
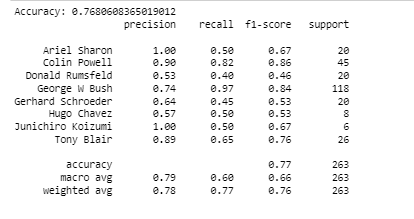
You need to use another gamma value mentioned above. Report the performance of the model.
"""Step four: continued"""
svc2 = SVC(kernel='rbf', class_weight='balanced', C=10, gamma=0.001)
model2 = svc2.fit(scaled_trnX, Sytrain)
"""Validate on the validation set and report the performance"""
vyfit2 = model2.predict(scaled_valX)
"""Performance measurements"""
from sklearn import metrics
print('Accuracy:', metrics.accuracy_score( vtest, vyfit2 )) # ground trueth i.e the label of validation test compared with the
from sklearn.metrics import classification_report
print(classification_report(vtest, vyfit2,
target_names=faces.target_names))output:
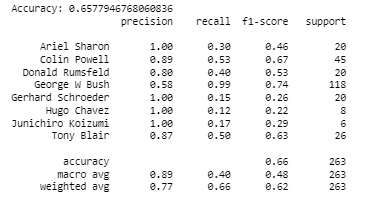
You need to use the third gamma value mentioned above. Report the performance of the model.
### """Step four: continued"""
svc3 = SVC(kernel='rbf', class_weight='balanced', C=10, gamma=0.0007)
model3 = svc3.fit(scaled_trnX, Sytrain)
"""Validate on the validation set and report the performance"""
vyfit3 = model3.predict(scaled_valX)
"""Performance measurements"""
from sklearn import metrics
print('Accuracy:', metrics.accuracy_score( vtest, vyfit3 )) # ground trueth i.e the label of validation test compared with the
from sklearn.metrics import classification_report
print(classification_report(vtest, vyfit3,
target_names=faces.target_names))output:
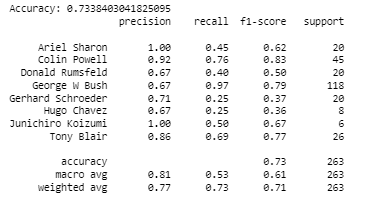
Choose the most suitable gamma value by comparing results obtained from the three fitted models
suitable_gamma = 0.005
Further test the selected parameters on the test set
First, you need to normalise the training set and the test set. Note that the training set is the original one including both the smaller training set and the validation set. Again, it is important that the scaling parameters should come from the training set, which should be used to normalise both the training set and the test set.
Finish the normalisation.
scaler = preprocessing.StandardScaler().fit(Xtrain)
scaled_X = scaler.transform(Xtrain)
scaled_tstX = scaler.transform(Xtest) Next, you need to fit an SVM model with the most suitable parameters obtained from Step four, test the trained model on the test set, and report the performance.
svc_final = SVC(kernel='rbf', class_weight='balanced', C=10, gamma=suitable_gamma)
model_final = svc_final.fit(scaled_X, ytrain)
yfit_test = model_final.predict(scaled_tstX)
from sklearn import metrics
print('Accuracy:', metrics.accuracy_score(ytest,yfit_test))
print(classification_report(ytest, yfit_test,
target_names=faces.target_names)) # f1 score is low try more gamma valuesoutput:

Which person's face images have the highest accuracy rate? Which person's face images have the lowest accuracy rate? Can you find the misclassified predictions?
from sklearn.metrics import confusion_matrix
#use Seaborn plotting defaults
import seaborn as sns; sns.set()
mat = confusion_matrix(ytest, yfit_test)
sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False,
xticklabels=faces.target_names,
yticklabels=faces.target_names)
plt.xlabel('true label')
plt.ylabel('predicted label');output:
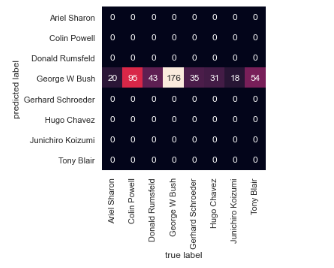
Advanced task: Learn how to do an exhaustive search over specified parameter values.
You can do a grid search using sklearn.grid_search.GridSearchCV. To understand how it works, you need to know what the cross-validation (CV) method is and how it works. A gentle introduction about CV can be viewed here.
Send your project requirement details at:
realcode4you@gmail.com to get any help in machine learning Face Recognition related task
Komentáře